英文原文链接:https://weblogs.java.net/blog/2007/11/27/consistent-hashing[1]
最近一段时间醉心于研究一致性哈希算法。本文所介绍的算法思想,早在1997年就已被 David Karger等人的在 论文中[2]提出,直到最近人们才发现这种思想可以运用到很多领域,从亚马逊的Dynamo[3]到memcached。所以,我们不禁要问,什么是一致性哈希 以及 为什么你要关注它。
由于使用分布式缓存(比如web缓存)时会遇到各种局限性,促成了对一致性哈希的需求。比如你有N台cache服务器(后文简称 cache),那么如何将一个对象object映射到N个cache上来进行负载均衡?通用的方式是计算对象的哈希值取模 hash(object) mod N 来完成。但是如果增加或者删除某个cache,那么这种方式就不会完美地工作。因为这必然导致每个对象都需要映射到新的位置上,意味着几乎所有的cache突然间都失效了。对服务器而言,这会是一场灾难,因为洪水般的访问直接冲向后台服务器。(这就是为什么你要关注它——一致性哈希就是用来阻止这种灾难的发生。)
当使用一致性哈希算法进行映射的时候,一切变得完美了:增加一个cache,它会公平地从其他的cache获取映射关系;删除一个cache,原先属于它的映射关系将被公平地分配给集群中其他cache。这就是一致性哈希所做的,尽可能小地改变已存在的映射关系。
一致性哈希算法的基本思想就是将对象和cache都使用相同的哈希算法。这样,可以实现将cache和对象映射到同一个哈希数值空间。如果移除一个cache,它对应的映射关系将被邻近的一个cache节点接管,其他的cache节点保持不变。
演示
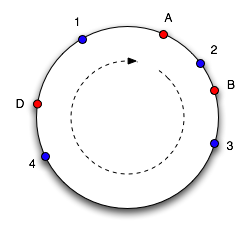
让我们透过细节看本质。哈希算法的作用是将对象和cache映射到一个数值空间。熟悉Java编程的屌丝都很熟悉它,Object.hashCode()方法返回一个从$-2^{31}$ 到 $2^{31}-1$之间的值。想象一下,将这个范围的值映射到一个头尾相接的圆环上。如图所示,将Objects(1,2,3,4) 和 caches(A,B,C)通过哈希值映射到一个圆环上。
为确定对象的映射的cache,以顺时针方向从对象出发,直到遇见一个cache,那么就将该对象存储到这个cache上。

从上图可以得到,对象1和对象4属于cache A,对象2属于cache B,对象3属于cache C;
假设移除cache C,那么对象3将属于cache A,其他的对象映射关系未发生改变;
假设新增cache D,那么对象3和对象4将被映射到cache D,而对象1仍然属于cache A,如图所示。
除了哈希数值区间段被分配到每个cache的长度是偶然随意的,上述机制会工作得很好。由于本质上的随意性,对象有可能不能被均匀地映射到cache上。为解决这种问题,引入虚拟节点的概念。“虚拟节点”是实际节点在哈希数值空间的复制品。cache无论何时加入,都将在哈希数值空间中创建对应几个虚拟节点。
通过下图中的模拟实验的数据,展示了虚拟节点的作用。在该次实验中,使用虚拟节点技术将10,000个对象映射到10个cache上。X轴表示每个cache对应的虚拟节点个数(呈对数级分布)。当该值很小的时候,Y轴显示的每个cache映射到的对象数目的标准非常高,由此表明对象映射非常不均衡;增大虚拟节点的数目,映射变得均匀。实验显示每个cache对应100或200个虚拟节点时,映射的均匀程度是可接受的(标准差介于5% - 10%)。

实现
这儿给出一个Java版的一致性哈希的简单实现。为达到有效的一致性哈希效果,混合性很好的hash函数至关重要。许多Object的hashCode并未满足这一点,很多时候它们只能产生一个小的严格的整型值。所以给出的实现提供了HashFunction接口,允许定制哈希策略。MD5哈希是一个好的选择。
1 | import java.util.Collection; |
代码中circle是一个键值顺序存储的Map,key表示哈希值,value对应cache(以T表示)。当ConsistentHash对象被创建时,每个cache被多次添加进circle(具体数目由numberOfReplicas控制)。每个虚拟节点映射的位置通过哈希cache节点和数字后缀来得到,每个真实的cache节点存储到这些虚拟节点对应的虚拟节点上。
对象的哈希值,被用来从map中寻找映射的cache节点(get方法)。多数情况下,对象的哈希值不会命中circle中已有的节点(因为即便使用虚拟节点,哈希值的空间也远远大于cache节点的数目),此时需要从tail map中寻找第一个键值。如果tail map为空,则从circle环绕寻找第一个命中的哈希值。
应用
那么如何使用一致性哈希?大多数时候,你更想从类库得到它,而非自己编码实现。如上提到的分布式内存缓存系统 memcached,如今已有专门的客户端来提供一致性哈希。由Last.fm 的 Richard Jones 实现的 ketama[4]是第一个实现,Dustin Sallings给出了Java的实现[5]。需要指出的是,只有客户端需要实现一致性哈希算法,缓存服务端无需改变。其他诸如Chord【一个分布式哈希表实现】 和 亚马逊的Dynamo 【一个KV存储系统】,都采用了一致性哈希算法。
参考资料:
[1] Consistent Hashing:http://blog.csdn.net/sparkliang/article/details/5279393
[2] Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web:http://dl.acm.org/citation.cfm?id=258660
[3] 亚马逊 Dynamo:http://www.allthingsdistributed.com/2007/10/amazons_dynamo.html
[4] ketama:http://www.audioscrobbler.net/development/ketama/
[5] Dustin Sallings对一致性哈希的Java实现:https://github.com/dustin/java-memcached-client
译者注:
原文并未能很好地阐述一致性哈希的思想,推荐阅读如下两篇博文: