特别注明:本文翻译自 Getting started with Storm 第四章,以作学习交流之用,非盈利性质。如需转载,请以超链接形式标明文章原始出处和作者信息及版权声明。
本章,你将学习到最被经常用来设计 topology(spout)的策略以及 spout 是如何具有容错能力的。
4.1 可靠 vs. 不可靠消息
当设计 topology 时,消息的可靠性是浮现在脑海中最重要的一件事。如果一个消息不能被处理,你需要决定如何处理这条消息以及整个topology需要做什么。比如,当处理银行存款业务时,很重要的一点事不能丢失任何一条交易消息。但是如果你处理上百万条tweet信息时来寻找某些统计指标时,一条丢失的消息对指标的准确性没有影响。
在 Storm 中,保证对每个 topology 的消息的可靠性是作者的责任。这包含一个 trade-off。一个可靠的 topology 必须可能需要更多资源来管理丢失的消息。一个低可靠的 topology 可能会丢失一些消息,但是需要更少的资源。无论选择哪种可靠性策略,Storm 都提供了工具区实现它。
在 spout 中管理可靠性,可以在发射的时候(collector.emit(new Values(...), tupleId))的时候往 tuple 中添加一个消息 ID。当一个 tuple 被处理正确或失败,ack或fail方法会被调用。只有在 tuple 被所有目标 bolt 和所有锚定 bolt(第五章将介绍如何将一个 bolt 锚定到一个 tuple)处理完,tuple 处理才算成功。
处理 tuple 失败的情形有:
目标 spout 调用
collector.fail(tuple)处理时间超过配置的超时时间
来看一个例子。想象一下你正在处理银行交易,你有如下需求:
如果一个交易失败,重发消息
如果交易多次失败,终止 topology
创建一个 spout,发送100个随机的交易 ID,一个接收 tuple 但是会 80% 失败的 bolt(你可以从 ch04-spout example中找到所有源码)。实现这个 spout,使用一个 Map来发射交易消息 tuple,这样就很容易重发消息。
1 | public void nextTuple() { |
如果有需要被发送的消息,取得相关的交易信息并附加上标识 ID,以 tuple 形式发射出去,接着清空消息队列。需要说明的是,这儿调用clear方法清空 map 是安全的,因为nextTuple、fail和ack是修改 map 的唯一方法,它们都在同一个线程中。
维护两个 map:一个用来追踪等待被发送的交易信息,一个用来记录每个交易失败的次数。ack方法只是简单地从 list 中删除交易信息。
1 | public void ack(Object msgId) { |
fail方法决定是否需要重发交易信息或者当失败很多次后直接失败。
如果在 topology 中使用广播分组方式,一旦任意 bolt 失败,spout 的
fail方法都将被调用。
1 | public void fail(Object msgId) { |
首先,检查交易失败的次数。如果该交易失败了很多次,跑出一个RuntimeException来终止运行它的工作者。否则,保存失败次数然后将交易消息放到toSend队列中,这样当nextTuple执行时它会被再次发送。
Storm 节点不维护状态。如果将信息保存在内存中,一旦节点失效,你将失去所有保存的信息。
Storm 是一个快速失败系统。如果一个异常被抛出,topology 将失败,但是 Storm 会在一致状态下重启处理,从而可以恢复正常。
4.2 获取数据
你将在本节接触一些用来设计从多个数据源高效地收集数据的常用技术。
4.2.1 直接连接
在直接获取体系下,spout 直接连接上消息发射器。[如图4.1所示]
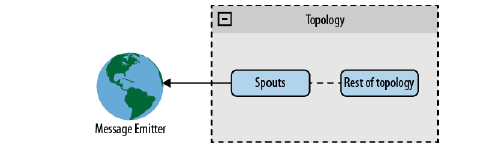
这种体系非常容易实现,适用于消息发射器是众所周知的设备或者设备组。众所周知的设备,指的是输出在启动时已知且在整个 topology 生命周期保持不变。未知设备是指在 topology 运行之后被加入的。众所周知的设备组,是一个组中所有设备在启动时就已知的设备组。
作为例子,创建一个使用 Twitter streaming API来读取Twitter数据流的 spout。这个 spout 将直接连接到作为消息发射器的该API上。以track参数来过滤所有匹配的公共 tweet 消息流。示例的所有代码可从 Github 上找到。
spout 从配置对象 object(track, user, password) 中获取连接参数,然后创建到API的连接(在本例中,使用Apache的DefaultHttpClient )。spout 每次读取一行信息,将其从 JSON 格式转换成 Java 对象,然后发射出去。
1 |
|
这里正在锁定
nextTuple方法,ack和fail方法永远不会被执行。实际应用中,建议在一个单独的线程中加锁,并且使用内部队列来交换信息(你将从下一章学习到如何这样做)。
这很好!
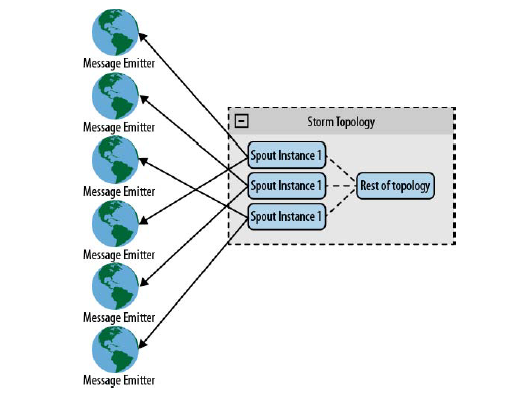
你正使用一个 spout 从 Twitter 数据流中读取数据。如果并行化这个 topology,你将可拥有几个 spout 来读取数据流的不同部分,这样做没有意义。那么如果你有多条需要读取的数据流,如何进行并行化处理呢?Storm 一个有趣的特性是,你可以从任意组件(spout/bolt)中读取TopologyContext。 你可以利用这个特性在多个 spout 实例间分配 数据流。
1 |
|
利用该技术,可以在数据源头分发 collector。同样的技术可以被用到其他情形下,比如从web服务器中读取日志文件。[如图4.2所示]
在前面的例子中,使用直接获取方式连接到已知的设备上。你可以使用同样的技术连接到未知设备上,只需要一个协调系统来维护设备列表。协调系统侦测列表变化、创建和销毁连接。比如,当从web服务器中收集日志文件的时候,web服务器列表可能会经常变化。当一个服务器被添加时,协调系统侦测到变化并为它创建新的spout,如图4.3所示。
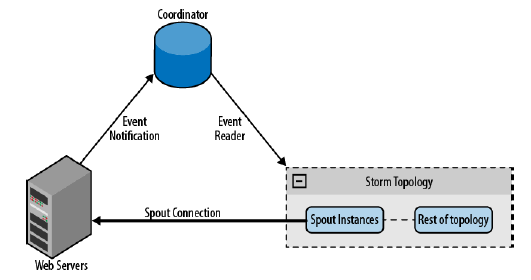
相比较其他方式,推荐创建从spout到消息发射源的连接。如果一台运行了 spout 的机器宕机了,Storm 将在另一台机器上重启这个 spout。相比较消息发射源需要追踪spout 运行在那台机器上,spout 定位消息发射源是更容易的做法。
4.2.2 队列消息
第二种途径是将 spout 连接到一个排队系统,该系统从消息发射源接受消息,并能够让 spout 消费消息。使用排队系统的优势是,它可以作为数据源和 spout 之间的中间件。许多情况下,你可以使用排队系统的消息重放机制来实现可靠的队列。这意味着,你不需要关注消息发射器的任何信息;相比直接连接方式,能够更方便地处理发射器的添加和删除。但是该结构的问题在于,队列将成为失败点,你需要为处理流添加新的一层结构。
下图显示了该架构的概貌。
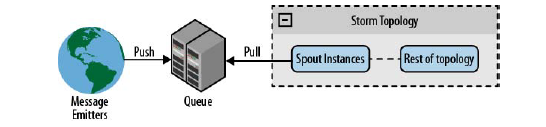
你可以使用循环拉或者哈希队列(将队列消息按照哈希值划分,然后发送到 spout 或者创建新的队列)来并行化队列的处理,在多个 spout 间划分消息。
创建一个示例,使用 Redis 作为队列系统,相对应的 Java 库是 Jedis。 在这个示例中,创建一个日志处理器从一个未知的数据源收集日志:使用lpush将消息压入队列,使用blpop来等待消息。如果有多个处理,使用blpop可以循环接收消息。
为了从Redis中检索消息,在 spout 的open方法中创建一个线程(使用线程可以避免锁住nextTuple方法所在的主循环)。
1 | new Thread(new Runnable() { |
该线程唯一的目的是创建连接并执行blpop指令。当一个消息被接收后,它被添加到一个内部的、可被nextTuple方法消费的消息队列。这儿,你可以看出,Redis 队列是一个源,你不知道哪个是消息的发射者或是他们的数量。
简易不要为 spout 创建许多线程,因为每个 spout 运行在不同的线程中。与其创建很多线程,不如增加并行度。这将以分布式方式在 Storm 集群中创建更多的线程。
在nextTuple方法中,唯一需要做的事情就是接受消息并且发射它们。
1 | public void nextTuple() { |
你可以修改 spout 使其利用 Redis 的消息重放功能来使得 topology 变得可靠。
4.2.3 DRPC
DRPCSpout 是一个实现了从 DRPC 服务器接收函数调用并处理它的 spout(参见第三章的示例)。在大多数情况下,backtype.storm.drpc.DRPCSpout足够使用了,但是你也可以使用Storm包中的 DRPC 类来创建自己的实现类。
4.3 总结
你已经看到了常用的 spout 实现模式、优点以及如何让消息变得可靠。基于你要解决的问题来构建 spout 通信是很重要的。没有一个适合所有 topology 的架构。如果你知道源或者能够控制它们,你可以使用直接连接方式;如果你需要添加未知源或者从多种源接收消息的能力,队列连接会是更好的选择。如果你需要在线处理,你需要使用DBPCSpouts或类似的实现。
尽管你已经知道三种主要的连接方式,仍然有无数种方式去实现它,这取决于你的需求。