特别注明:本文翻译自 Getting started with Storm 第八章,以作学习交流之用,非盈利性质。如需转载,请以超链接形式标明文章原始出处和作者信息及版权声明。
在Storm中,如本书前面提到的,你可以使用 ack 和 fail策略来保证消息被处理。但是如果消息重放了呢?如何保证不被重复计数?
事务 Topology 是 Storm 0.7.0 里面的新特性,可以使用消息原语来保证消息以安全的方式重放,且仅被处理一次。没有事务性 topology 的支持,你无法以并发的、容错的方式百分百准确地进行统计。
事务性 topology 是建立在标准 spout 和 bolt 之上的抽象。
8.1 设计 在一个事务性 topology 中,Storm 使用并行和顺序 tuple 的混合处理方式。Spout 产生批次 tuple,被 bolt 并行处理。其中的某些 bolt 是已知的被称为提交者,它们以一种严格的方式提交已处理的批量 tuple。这意味着,如果有两个批次,每个批次拥有五个 tuple,两批 tuplee 都会被 bolt 并行处理,但是提交者 bolt 直到第一个 tuple 被成功提交后才会提交。
在处理事务性 topology 时,从源重放甚至多次重放一批 tuple 是很重要的。所以确保数据源也即 所连接的 spout 具有这样的能力。
这可以被描述为如下步骤或阶段:
将以上两阶段称为 Storm 事务。
Storm 使用 Zookeeper 来存储事务元数据。默认情况下,就采用 topology 使用的那个 Zookeeper 来存储元数据。可以通过修改配置项transactional.zookeeper.servers 和 transactional.zookeeper.port来覆盖。
8.2 事务实战 我们通过创建一个 Twitter 分析工具来讲解事务是如何工作的。从 Redis 数据库中读取 tweets,通过一系列 bolt 来处理,并将结果保存到另一个 Redis 数据库。这些结果包括所有标签和他们在 tweets 中出现的频率,出现在 tweets 中的用户列表和数量,以及一个用户使用的标签和频率列表。
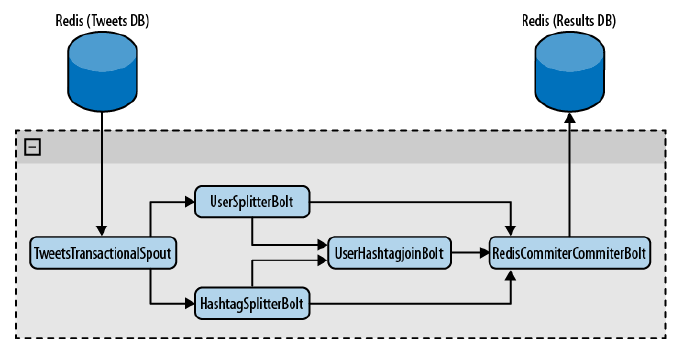
构造如图8.1所示的 topology。
如你所见,TweetsTransactionalSpout这个 spout 连接 tweets 数据库,并向 topology 中发射一批 tuple。UserSplitterBolt和HashtagSplitterBolt从 spout 中接收 tuple。UserSplitterBolt转换 tweets 并从中寻找用户(即 @ 之后的单词),并通过自定义的users流发射这些单词。HashtagSplitterBolt同样也转换 tweets,从中寻找前缀为#的单词,并通过自定义的hashtags流来发射这些单词。第三个 bolt UserHashtagJoinBolt接收前面两个 bolt 发出的内容,对一个 特定用户的tweet中某个标签出现的次数。为了计数和发射结果,该 bolt 是一个 BaseBatchBolt(后面会设计更多细节)。
最终,RedisCommitterBolt这个最后的 bolt 接收从上述三个 bolt 发射出的三个流。在一个事务中,它完成所有计数,并且一旦完成一批 tuple 的处理就将所有结果保存到Redis 中。该bolt 就是独特的提交者 bolt,将在下一节进行介绍。
通过TransactionalTopologyBuilder创建 topology,如下代码块所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 TransactionalTopologyBuilder builder = new TransactionalTopologyBuilder("test" , "spout" , new TweetsTransactionalSpout());builder.setBolt("users-splitter" , new UserSplitterBolt(), 4 ).shuffleGrouping("spout" ); builder.setBolt("hashtag-splitter" , new HashtagSplitterBolt(), 4 ).shuffleGrouping("spout" ); builder.setBolt("user-hashtag-merger" , new UserHashtagJoinBolt(), 4 ) .fieldsGrouping("users-splitter" ,"users" , new Fields("tweet_id" )) .fieldsGrouping("hashtag-splitter" , "hashtags" , new Fields("tweet_id" )); builder.setBolt("redis-committer" , new RedisCommiterCommiterBolt()) .globalGrouping("users-splitter" ,"users" ) .globalGrouping("hashtag-splitter" , "hashtags" ) .globalGrouping("user-hashtag-merger" );
让我们来看看事务性 topology 中 spout 的实现。
8.2.1 Spout 事务 topology 中的 spout 与标准 spout 差异很大。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class TweetsTransactionalSpout extends BaseTransactionalSpout <TransactionMetadata > ``` 如类定义中所示,``TweetsTransactionalSpout`` 继承自带有一个特定泛型的``BaseTransactionalSpout``。设置的泛型是事务元数据。它在从源发射一批 tuple 时被使用。 本例中,``TransactionMetadata``定义如下: ```java public class TransactionMetadata implements Serializable private static final long serialVersionUID = 1L ; long from; int quantity; public TransactionMetadata (long from, int quantity) this .from = from; this .quantity = quantity; } }
在这里存储from和quantity,来告诉如何具体地生成一批 tuple。
为了完成spout 的实现,需要实现如下三个方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @Override public ITransactionalSpout.Coordinator<TransactionMetadata> getCoordinator (Map conf, TopologyContext context) { return new TweetsTransactionalSpoutCoordinator(); } @Override public backtype.storm.transactional.ITransactionalSpout.Emitter<TransactionMetadata> getEmitter (Map conf, TopologyContext context) { return new TweetsTransactionalSpoutEmitter(); } @Override public void declareOutputFields (OutputFieldsDeclarer declarer) declarer.declare(new Fields("txid" , "tweet_id" , "tweet" )); }
在getCoordinator方法中,告诉 Storm 哪个类将用来协调一批 tuple 的生成。getEmitter 用来告诉 Storm 哪个类负责从源读取一批 tuple 并在 topology 中以流的方式发射它们。最后,如前面所做的,需要声明哪些字段被发射了。
8.2.1.1 RQ 为了使示例更简单点,我们将 Redis 的相关操作封装在同一个类中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 public class RQ public static final String NEXT_READ = "NEXT_READ" ; public static final String NEXT_WRITE = "NEXT_WRITE" ; Jedis jedis; public RQ () jedis = new Jedis("localhost" ); } public long getAvailableToRead (long current) return getNextWrite() - current; } public long getNextRead () String sNextRead = jedis.get(NEXT_READ); if (sNextRead == null ) return 1 ; return Long.valueOf(sNextRead); } public long getNextWrite () return Long.valueOf(jedis.get(NEXT_WRITE)); } public void close () jedis.disconnect(); } public void setNextRead (long nextRead) jedis.set(NEXT_READ, "" +nextRead); } public List<String> getMessages (long from, int quantity) String[] keys = new String[quantity]; for (int i = 0 ; i < quantity; i++) keys[i] = "" +(i+from); return jedis.mget(keys); } }
仔细阅读每个方法的实现,确保你理解它们做些什么工作。
8.2.1.2 Coordinator 看看本例中协调类的实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public static class TweetsTransactionalSpoutCoordinator implements ITransactionalSpout .Coordinator <TransactionMetadata > TransactionMetadata lastTransactionMetadata; RQ rq = new RQ(); long nextRead = 0 ; public TweetsTransactionalSpoutCoordinator () nextRead = rq.getNextRead(); } @Override public TransactionMetadata initializeTransaction (BigInteger txid, TransactionMetadata prevMetadata) long quantity = rq.getAvailableToRead(nextRead); quantity = quantity > MAX_TRANSACTION_SIZE ?MAX_TRANSACTION_SIZE : quantity; TransactionMetadata ret = new TransactionMetadata(nextRead, (int )quantity); nextRead += quantity; return ret; } @Override public boolean isReady () return rq.getAvailableToRead(nextRead) > 0 ; } @Override public void close () rq.close(); } }
需要注意的是,在一个 topology 中仅有一个 coordinator 实例。当协调者被实例化后,它会从 Redis 检索出一个序列,来告诉下一个被读取的 tweet是哪一个。第一次时,该值是 1,意味着接下来要读取的 tweet 是第一条。
第一个被调用的方法是isReady。它总是在initializeTransaction之前被调用,来确保源准备好被读取。相应地返回 true 或者 false。本例中,检索tweet的数量,并跟已读取的数量比较。两者之间的差值是可以读取的tweet的数量。如果该值大于0,意味着有可读的 tweet。
最后,initializeTransaction被执行。如你所见,将txid和prevMetadata作为参数。第一个参数是 Storm 产生的唯一的事务 ID,用来标识产生的批量 tuple。preMetadata是之前事务的协调者产生的元数据。
本例中,首先确认有多少 tweet 可以被读取。一旦整理好了,创建一个新的TransactionMetadata,指明哪一个是被第一个读取的 tweet 以及读取的数量。
元数组一返回,Storm 将它们和 txid 存储到 zookeeper中。这保证了一旦有错误,Storm 可以重新发送该批次 tuple。
8.2.1.3 Emitter 创建事务spout的最后一步是实现发射器。
让我们从下面的实现开始:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 ITransactionalSpout.Emitter<TransactionMetadata> { RQ rq = new RQ(); public TweetsTransactionalSpoutEmitter () } @Override public void emitBatch (TransactionAttempt tx, TransactionMetadata coordinatorMeta, BatchOutputCollector collector) rq.setNextRead(coordinatorMeta.from+coordinatorMeta.quantity); List<String> messages = rq.getMessages(coordinatorMeta.from, coordinatorMeta.quantity); long tweetId = coordinatorMeta.from; for (String message : messages) { collector.emit(new Values(tx, "" +tweetId, message)); tweetId++; } } @Override public void cleanupBefore (BigInteger txid) } @Override public void close () rq.close(); } }
发射器读取数据源、发射到某个流。对于相同的事务 ID 和事务元数据,发射器总是能发射相同批次的 tuple。以这种方式,如果一批的处理出错了,Storm 可以重复让发射器同样的事务 ID 和事务元数据,从而确保该批 tuple 被重新发送。Storm 将在 TransactionAttempt中增加 attempt id 。这样就可以知道该批次被重新发送了。
emitBatch是一个很重要的方法。在该方法中,使用 metadata 作为参数从 Redis 中获取 tweet。同样在 Redis 中增加序列来跟踪当前有多少 tweet 被读取了。当然,发射 tweet 到 topology中。
8.2.2 Bolt 首先,来看看该 topology 的标准 bolt。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 public class UserSplitterBolt implements IBasicBolt private static final long serialVersionUID = 1L ; @Override public void declareOutputFields (OutputFieldsDeclarer declarer) declarer.declareStream("users" , new Fields("txid" , "tweet_id" , "user" )); } @Override public Map<String, Object> getComponentConfiguration() { return null ; } @Override public void prepare (Map stormConf, TopologyContext context) } @Override public void execute (Tuple input, BasicOutputCollector collector) String tweet = input.getStringByField("tweet" ); String tweetId = input.getStringByField("tweet_id" ); StringTokenizer strTok = new StringTokenizer(tweet, " " ); TransactionAttempt tx = (TransactionAttempt)input.getValueByField("txid" ); HashSet<String> users = new HashSet<String>(); while (strTok.hasMoreTokens()) { String user = strTok.nextToken(); if (user.startsWith("@" ) && !users.contains(user)) { collector.emit("users" , new Values(tx, tweetId, user)); users.add(user); } } } @Override public void cleanup () } }
如本章前面所述,UserSplitBolt 接收 tuple,解析 tweet 文本,发射@后面的词汇或者Twitter 用户。HashtagSplitter以一种简单的方式工作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 public class HashtagSplitterBolt implements IBasicBolt private static final long serialVersionUID = 1L ; @Override public void declareOutputFields (OutputFieldsDeclarer declarer) declarer.declareStream("hashtags" , new Fields("txid" , "tweet_id" , "hashtag" )); } @Override public Map<String, Object> getComponentConfiguration() { return null ; } @Override public void prepare (Map stormConf, TopologyContext context) } @Override public void execute (Tuple input, BasicOutputCollector collector) String tweet = input.getStringByField("tweet" ); String tweetId = input.getStringByField("tweet_id" ); StringTokenizer strTok = new StringTokenizer(tweet, " " ); TransactionAttempt tx = (TransactionAttempt)input.getValueByField("txid" ); HashSet<String> words = new HashSet<String>(); while (strTok.hasMoreTokens()) { String word = strTok.nextToken(); if (word.startsWith("#" ) && !words.contains(word)) { collector.emit("hashtags" , new Values(tx, tweetId, word)); words.add(word); } } } @Override public void cleanup () } }
看看UserHashtagJoinBolt中发生了什么。首先需要注意的重要的事情是BaseBatchBolt。这意味着execute方法将会用来处理接收到的 tuple,但是不会发射任何新的 tuple。最后,当该批次结束后,Storm 调用finishBatch方法。
1 2 3 4 5 6 7 8 9 10 11 12 public void execute (Tuple tuple) String source = tuple.getSourceStreamId(); String tweetId = tuple.getStringByField("tweet_id" ); if ("hashtags" .equals(source)) { String hashtag = tuple.getStringByField("hashtag" ); add(tweetHashtags, tweetId, hashtag); } else if ("users" .equals(source)) { String user = tuple.getStringByField("user" ); add(userTweets, user, tweetId); } }
由于需要将一条tweet中所有的标签与该tweet中提到的用户关联起来并且统计出现的次数,因此要对前边bolt的两条流做连接。对整个批次都这样处理,一旦完成了,finishBatch方法会被调用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 @Override public void finishBatch () for (String user : userTweets.keySet()) { Set<String> tweets = getUserTweets(user); HashMap<String, Integer> hashtagsCounter = new HashMap<String, Integer>(); for (String tweet : tweets) { Set<String> hashtags = getTweetHashtags(tweet); if (hashtags != null ) { for (String hashtag : hashtags) { Integer count = hashtagsCounter.get(hashtag); if (count == null ) count = 0 ; count ++; hashtagsCounter.put(hashtag, count); } } } for (String hashtag : hashtagsCounter.keySet()) { int count = hashtagsCounter.get(hashtag); collector.emit(new Values(id, user, hashtag, count)); } } }
在该方法中,对每个用户-标签和它们出现的次数产生并发射 tuple。
8.2.3 提交者 Bolt 你已经知道,一批tuple会被协调者和发射器发送到topology中。这些批量tuple以无序的方式被并行处理。协调者 bolt 是实现了 ICommitter接口的特殊 bolt,或者在TransactionalTopologyBuilder中被setCommiterBolt设置过。它与普通批量 bolt 的区别是当该批次准备好被提交时,会执行提交者 bolt 的finishBatch方法。这发生在所有前面的事务被成功提交后。另外,finishBatch方法被顺序执行。所以,如果事务ID 为1 和事务ID 为2的批次在 topology 中被并行处理,事务ID 2 的 提交者bolt的 finishBatch方法将在事务ID 1的 bolt 的 finishBatch方法被成功执行后才会被执行。
下面是该类的实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 public class RedisCommiterCommiterBolt extends BaseTransactionalBolt implements ICommitter public static final String LAST_COMMITED_TRANSACTION_FIELD = "LAST_COMMIT" ; TransactionAttempt id; BatchOutputCollector collector; Jedis jedis; @Override public void prepare (Map conf, TopologyContext context, BatchOutputCollector collector, TransactionAttempt id) this .id = id; this .collector = collector; this .jedis = new Jedis("localhost" ); } HashMap<String, Long> hashtags = new HashMap<String, Long>(); HashMap<String, Long> users = new HashMap<String, Long>(); HashMap<String, Long> usersHashtags = new HashMap<String, Long>(); private void count (HashMap<String, Long> map, String key, int count) Long value = map.get(key); if (value == null ) value = (long ) 0 ; value += count; map.put(key, value); } @Override public void execute (Tuple tuple) String origin = tuple.getSourceComponent(); if ("users-splitter" .equals(origin)) { String user = tuple.getStringByField("user" ); count(users, user, 1 ); } else if ("hashtag-splitter" .equals(origin)) { String hashtag = tuple.getStringByField("hashtag" ); count(hashtags, hashtag, 1 ); } else if ("user-hashtag-merger" .equals(origin)) { String hashtag = tuple.getStringByField("hashtag" ); String user = tuple.getStringByField("user" ); String key = user + ":" + hashtag; Integer count = tuple.getIntegerByField("count" ); count(usersHashtags, key, count); } } @Override public void finishBatch () String lastCommitedTransaction = jedis.get(LAST_COMMITED_TRANSACTION_FIELD); String currentTransaction = "" +id.getTransactionId(); if (currentTransaction.equals(lastCommitedTransaction)) return ; Transaction multi = jedis.multi(); multi.set(LAST_COMMITED_TRANSACTION_FIELD, currentTransaction); Set<String> keys = hashtags.keySet(); for (String hashtag : keys) { Long count = hashtags.get(hashtag); multi.hincrBy("hashtags" , hashtag, count); } keys = users.keySet(); for (String user : keys) { Long count = users.get(user); multi.hincrBy("users" , user, count); } keys = usersHashtags.keySet(); for (String key : keys) { Long count = usersHashtags.get(key); multi.hincrBy("users_hashtags" , key, count); } multi.exec(); } @Override public void declareOutputFields (OutputFieldsDeclarer declarer) } } ``` 非常浅显易懂,但是在 ``finishBatch``中需要注意一个重要的细节。 ```java ... multi.set(LAST_COMMITED_TRANSACTION_FIELD, currentTransaction); ...
这里在数据库中存储最后被提交的事务ID。为什么要这样做?记住当一个事务失败时,Storm 将在必要情形下多次重放它。如果不确定已经处理了该事务,那么结果将被重复计算,这样导致事务性 topology 没有起到该有的作用。所以记住:存储最后一个被提交的事务ID并且在提交之前检查它。
8.2 分区事务 Spouts Spout 从某个分区集合中读取一批 tuple 是很平常的事情。接着上面的例子,你可以使用多个 Redis 数据库来分散地存储 tweets。通过实现IPartitionedTransactionalSpout,Storm 提供了一些工具来管理每个分区的状态并确保重放能力。
让我们来看看如何修改前面的TweetsTransactionalSpout使其可以处理分区。
首先,继承 BasePartitionedTransactionalSpout,该类实现了IPartitionedTransactionalSpout接口。
1 2 3 4 public class TweetsPartitionedTransactionalSpout extends BasePartitionedTransactionalSpout <TransactionMetadata > ... }
告诉 Storm 哪一个是协调者。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public static class TweetsPartitionedTransactionalCoordinator implements Coordinator @Override public int numPartitions () return 4 ; } @Override public boolean isReady () return true ; } @Override public void close () } }
在本例中,协调者很简单。在numPartitions方法中,告诉 Storm 有多少分区。同时注意不返回任何元数据。元数据在IPartitionedTransactionalSpout中被发射器直接管理。
来看看发射器如何实现的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 public static class TweetsPartitionedTransactionalEmitter implements Emitter <TransactionMetadata > PartitionedRQ rq = new PartitionedRQ(); @Override public TransactionMetadata emitPartitionBatchNew (TransactionAttempt tx, BatchOutputCollector collector, int partition, TransactionMetadata lastPartitionMeta) long nextRead; if (lastPartitionMeta == null ) nextRead = rq.getNextRead(partition); else { nextRead = lastPartitionMeta.from + lastPartitionMeta.quantity; rq.setNextRead(partition, nextRead); } long quantity = rq.getAvailableToRead(partition, nextRead); quantity = quantity > MAX_TRANSACTION_SIZE ? MAX_TRANSACTION_SIZE : quantity; TransactionMetadata metadata = new TransactionMetadata(nextRead, (int )quantity); emitPartitionBatch(tx, collector, partition, metadata); return metadata; } @Override public void emitPartitionBatch (TransactionAttempt tx, BatchOutputCollector collector, int partition, TransactionMetadata partitionMeta) if (partitionMeta.quantity <= 0 ) return ; List<String> messages = rq.getMessages(partition, partitionMeta.from,partitionMeta.quantity); long tweetId = partitionMeta.from; for (String msg : messages) { collector.emit(new Values(tx, "" +tweetId, msg)); tweetId ++; } } @Override public void close () } }
该类中有两个重要的方法,emitPartitionBatchNew和emitPartitionBatch。在emitPartitionBatch中,从Storm 接收 partition参数,该参数告诉你从哪个分区中检出批量tuple。在该方法中,决定读取哪个tweets,产生管理的元数据,调用emitBatch方法,并返回元数据。元数据会被立即存储到Zookeeper。
由于事务遍布所有分区,Storm 将为每个分区分配相同的事务ID。在emitPartitionBatch方法中,读取分区的 tweets,向topology中发射一批tuple。如果该批失败了,Storm 将通过元数据调用 emitPartitionBatch来重放该批数据。
8.3 不透明事务 Topology 目前为止,你可能会假定对于相同的事务ID,重放一批 tuple 是一直可以的。但是这种假设在某些场景下是不可行的。到底发生了什么?
事实证明,你仍然可以实现明确的语义,但是可能需要一些额外的开发工作,因为你需要在 Storm 重放事务的情形下保持之前的状态。因为当在不同时刻发射时你可以为相同的事务ID中获取不同的tuple,你需要重置到之前的状态并从那里开始。
比如,如果你对接收到的所有 tweets 进行计数,你已经计数到5。在最后一个ID为321的事务中,你计数了另外8个。你保存三个值:previousCount=5, currentCount=13和lastTransactionId=321。如果事务ID为321的事务被再次发射,且你得到了不同的tuple,你计数了四个而不是八个。提交者将侦测到相同的事务ID,它会将previousCount重置为5,加上新得到的4,将currentCount更新为9。
另外,当前一个事务被取消的话,所有并行处理的事务都会被取消掉。这保证了你在其中没有错失任何东西。
Spout 需要实现IOpaquePartitionedTransactionalSpout,如你所见,协调者和发射器都很简单。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 public static class TweetsOpaquePartitionedTransactionalSpoutCoordinator implements IOpaquePartitionedTransactionalSpout .Coordinator @Override public boolean isReady () return true ; } } public static class TweetsOpaquePartitionedTransactionalSpoutEmitter implements IOpaquePartitionedTransactionalSpout .Emitter <TransactionMetadata PartitionedRQ rq = new PartitionedRQ(); @Override public TransactionMetadata emitPartitionBatch (TransactionAttempt tx, BatchOutputCollector collector, int partition, TransactionMetadata lastPartitionMeta) long nextRead; if (lastPartitionMeta == null ) nextRead = rq.getNextRead(partition); else { nextRead = lastPartitionMeta.from + lastPartitionMeta.quantity; rq.setNextRead(partition, nextRead); } long quantity = rq.getAvailableToRead(partition, nextRead); quantity = quantity > MAX_TRANSACTION_SIZE ? MAX_TRANSACTION_SIZE : quantity; TransactionMetadata metadata = new TransactionMetadata(nextRead, (int )quantity); emitMessages(tx, collector, partition, metadata); return metadata; } private void emitMessages (TransactionAttempt tx, BatchOutputCollector collector, int partition, TransactionMetadata partitionMeta) if (partitionMeta.quantity <= 0 ) return ; List<String> messages = rq.getMessages(partition, partitionMeta.from, partitionMeta.quantity); long tweetId = partitionMeta.from; for (String msg : messages) { collector.emit(new Values(tx, "" +tweetId, msg)); tweetId ++; } } public int numPartitions () return 4 ; } @Override public void close () } }
emitPartitionBatch方法很有趣,它接收前面提交的元数据。可以使用这些信息产生一批tuple。这批数据不必完全相同。如前所述,你可能无法重新制造出相同的批次数据。剩余的工作由提交者 bolt 使用之前的状态来处理。